| Slony-I 1.2.23 Documentation | ||||
|---|---|---|---|---|
| Prev | Fast Backward | Fast Forward | Next | |
8. Doing switchover and failover with Slony-I
8.1. Foreword
Slony-I is an asynchronous replication system. Because of that, it is almost certain that at the moment the current origin of a set fails, the final transactions committed at the origin will have not yet propagated to the subscribers. Systems are particularly likely to fail under heavy load; that is one of the corollaries of Murphy's Law. Therefore the principal goal is to prevent the main server from failing. The best way to do that is frequent maintenance.
Opening the case of a running server is not exactly what we should consider a "professional" way to do system maintenance. And interestingly, those users who found it valuable to use replication for backup and failover purposes are the very ones that have the lowest tolerance for terms like "system downtime." To help support these requirements, Slony-I not only offers failover capabilities, but also the notion of controlled origin transfer.
It is assumed in this document that the reader is familiar with the slonik utility and knows at least how to set up a simple 2 node replication system with Slony-I.
8.2. Controlled Switchover
We assume a current "origin" as node1 with one "subscriber" as node2 (e.g. - slave). A web application on a third server is accessing the database on node1. Both databases are up and running and replication is more or less in sync. We do controlled switchover using SLONIK MOVE SET.
At the time of this writing switchover to another server requires the application to reconnect to the new database. So in order to avoid any complications, we simply shut down the web server. Users who use pg_pool for the applications database connections merely have to shut down the pool.
What needs to be done, here, is highly dependent on the way that the application(s) that use the database are configured. The general point is thus: Applications that were connected to the old database must drop those connections and establish new connections to the database that has been promoted to the "master" role. There are a number of ways that this may be configured, and therefore, a number of possible methods for accomplishing the change:
The application may store the name of the database in a file.
In that case, the reconfiguration may require changing the value in the file, and stopping and restarting the application to get it to point to the new location.
A clever usage of DNS might involve creating a CNAME DNS record that establishes a name for the application to use to reference the node that is in the "master" role.
In that case, reconfiguration would require changing the CNAME to point to the new server, and possibly restarting the application to refresh database connections.
If you are using pg_pool or some similar "connection pool manager," then the reconfiguration involves reconfiguring this management tool, but is otherwise similar to the DNS/CNAME example above.
Whether or not the application that accesses the database needs to be restarted depends on how it is coded to cope with failed database connections; if, after encountering an error it tries re-opening them, then there may be no need to restart it.
A small slonik script executes the following commands:
lock set (id = 1, origin = 1); wait for event (origin = 1, confirmed = 2); move set (id = 1, old origin = 1, new origin = 2); wait for event (origin = 1, confirmed = 2);
After these commands, the origin (master role) of data set 1 has been transferred to node2. And it is not simply transferred; it is done in a fashion such that node1 becomes a fully synchronized subscriber, actively replicating the set. So the two nodes have switched roles completely.
After reconfiguring the web application (or pgpool ) to connect to the database on node2, the web server is restarted and resumes normal operation.
Done in one shell script, that does the application shutdown, slonik, move config files and startup all together, this entire procedure is likely to take less than 10 seconds.
You may now simply shutdown the server hosting node1 and do whatever is required to maintain the server. When slon node1 is restarted later, it will start replicating again, and soon catch up. At this point the procedure to switch origins is executed again to restore the original configuration.
This is the preferred way to handle things; it runs quickly, under control of the administrators, and there is no need for there to be any loss of data.
After performing the configuration change, you should, as Section 1, run the Section 5.1 scripts in order to validate that the cluster state remains in good order after this change.
8.3. Failover
If some more serious problem occurs on the "origin" server, it may be necessary to SLONIK FAILOVER to a backup server. This is a highly undesirable circumstance, as transactions "committed" on the origin, but not applied to the subscribers, will be lost. You may have reported these transactions as "successful" to outside users. As a result, failover should be considered a last resort. If the "injured" origin server can be brought up to the point where it can limp along long enough to do a controlled switchover, that is greatly preferable.
Slony-I does not provide any automatic detection for failed systems. Abandoning committed transactions is a business decision that cannot be made by a database system. If someone wants to put the commands below into a script executed automatically from the network monitoring system, well ... it's your data, and it's your failover policy.
The slonik command
failover (id = 1, backup node = 2);
causes node2 to assume the ownership (origin) of all sets that have node1 as their current origin. If there should happen to be additional nodes in the Slony-I cluster, all direct subscribers of node1 are instructed that this is happening. Slonik will also query all direct subscribers in order to determine out which node has the highest replication status (e.g. - the latest committed transaction) for each set, and the configuration will be changed in a way that node2 first applies those final before actually allowing write access to the tables.
In addition, all nodes that subscribed directly to node1 will now use node2 as data provider for the set. This means that after the failover command succeeded, no node in the entire replication setup will receive anything from node1 any more.
Note: Note that in order for node 2 to be considered as a candidate for failover, it must have been set up with the SLONIK SUBSCRIBE SET option forwarding = yes, which has the effect that replication log data is collected in sl_log_1/sl_log_2 on node 2. If replication log data is not being collected, then failover to that node is not possible.
Reconfigure and restart the application (or pgpool) to cause it to reconnect to node2.
Purge out the abandoned node
You will find, after the failover, that there are still a full set of references to node 1 in sl_node, as well as in referring tables such as sl_confirm; since data in sl_log_1/sl_log_2 is still present, Slony-I cannot immediately purge out the node.
After the failover is complete and node2 accepts write operations against the tables, remove all remnants of node1's configuration information with the SLONIK DROP NODE command:
drop node (id = 1, event node = 2);
Supposing the failure resulted from some catastrophic failure of the hardware supporting node 1, there might be no "remains" left to look at. If the failure was not "total", as might be the case if the node had to be abandoned due to a network communications failure, you will find that node 1 still "imagines" itself to be as it was before the failure. See Section 8.6 for more details on the implications.
After performing the configuration change, you should, as Section 1, run the Section 5.1 scripts in order to validate that the cluster state remains in good order after this change.
8.4. Failover With Complex Node Set
Failover is relatively "simple" if there are only two nodes; if a Slony-I cluster comprises many nodes, achieving a clean failover requires careful planning and execution.
Consider the following diagram describing a set of six nodes at two sites.
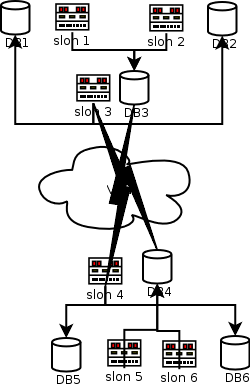
Let us assume that nodes 1, 2, and 3 reside at one data centre, and that we find ourselves needing to perform failover due to failure of that entire site. Causes could range from a persistent loss of communications to the physical destruction of the site; the cause is not actually important, as what we are concerned about is how to get Slony-I to properly fail over to the new site.
We will further assume that node 5 is to be the new origin, after failover.
The sequence of Slony-I reconfiguration required to properly failover this sort of node configuration is as follows:
Resubscribe (using SLONIK SUBSCRIBE SET ech node that is to be kept in the reformation of the cluster that is not already subscribed to the intended data provider.
In the example cluster, this means we would likely wish to resubscribe nodes 4 and 6 to both point to node 5.
include </tmp/failover-preamble.slonik>; subscribe set (id = 1, provider = 5, receiver = 4); subscribe set (id = 1, provider = 5, receiver = 4);
Drop all unimportant nodes, starting with leaf nodes.
Since nodes 1, 2, and 3 are unaccessible, we must indicate the EVENT NODE so that the event reaches the still-live portions of the cluster.
include </tmp/failover-preamble.slonik>; drop node (id=2, event node = 4); drop node (id=3, event node = 4);
Now, run FAILOVER.
include </tmp/failover-preamble.slonik>; failover (id = 1, backup node = 5);
Finally, drop the former origin from the cluster.
include </tmp/failover-preamble.slonik>; drop node (id=1, event node = 4);
8.5. Automating FAIL OVER
If you do choose to automate FAIL OVER , it is important to do so carefully. You need to have good assurance that the failed node is well and truly failed, and you need to be able to assure that the failed node will not accidentally return into service, thereby allowing there to be two nodes out there able to respond in a "master" role.
Note: The problem here requiring that you "shoot the failed node in the head" is not fundamentally about replication or Slony-I; Slony-I handles this all reasonably gracefully, as once the node is marked as failed, the other nodes will "shun" it, effectively ignoring it. The problem is instead with your application. Supposing the failed node can come back up sufficiently that it can respond to application requests, that is likely to be a problem, and one that hasn't anything to do with Slony-I. The trouble is if there are two databases that can respond as if they are "master" systems.
When failover occurs, there therefore needs to be a mechanism to forcibly knock the failed node off the network in order to prevent applications from getting confused. This could take place via having an SNMP interface that does some combination of the following:
Turns off power on the failed server.
If care is not taken, the server may reappear when system administrators power it up.
Modify firewall rules or other network configuration to drop the failed server's IP address from the network.
If the server has multiple network interfaces, and therefore multiple IP addresses, this approach allows the "application" addresses to be dropped/deactivated, but leave "administrative" addresses open so that the server would remain accessible to system administrators.
8.6. After Failover, Reconfiguring Former Origin
What happens to the failed node will depend somewhat on the nature of the catastrophe that lead to needing to fail over to another node. If the node had to be abandoned because of physical destruction of its disk storage, there will likely not be anything of interest left. On the other hand, a node might be abandoned due to the failure of a network connection, in which case the former "provider" can appear be functioning perfectly well. Nonetheless, once communications are restored, the fact of the FAIL OVER makes it mandatory that the failed node be abandoned.
After the above failover, the data stored on node 1 will rapidly become increasingly out of sync with the rest of the nodes, and must be treated as corrupt. Therefore, the only way to get node 1 back and transfer the origin role back to it is to rebuild it from scratch as a subscriber, let it catch up, and then follow the switchover procedure.
A good reason not to do this automatically is the fact that important updates (from a business perspective) may have been committed on the failing system. You probably want to analyze the last few transactions that made it into the failed node to see if some of them need to be reapplied on the "live" cluster. For instance, if someone was entering bank deposits affecting customer accounts at the time of failure, you wouldn't want to lose that information.
| Warning |
It has been observed that there can be some very confusing results if a node is "failed" due to a persistent network outage as opposed to failure of data storage. In such a scenario, the "failed" node has a database in perfectly fine form; it is just that since it was cut off, it "screams in silence." If the network connection is repaired, that node could reappear, and as far as its configuration is concerned, all is well, and it should communicate with the rest of its Slony-I cluster. In fact, the only confusion taking place is on that node. The other nodes in the cluster are not confused at all; they know that this node is "dead," and that they should ignore it. But there is not a way to know this by looking at the "failed" node. This points back to the design point that Slony-I is not a network monitoring tool. You need to have clear methods of communicating to applications and users what database hosts are to be used. If those methods are lacking, adding replication to the mix will worsen the potential for confusion, and failover will be a point at which there is enormous potential for confusion. |
If the database is very large, it may take many hours to recover node1 as a functioning Slony-I node; that is another reason to consider failover as an undesirable "final resort."